Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
IT技术分享,Java开发、日常开发技巧、好用开发工具分享
引言:为什…
MQTT协议概…

Eclipse基金…

1.设备影子…
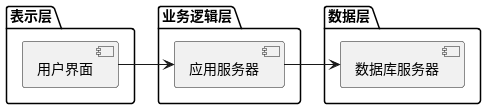
随着科技的进步和软件开发的不断发展,图形化表示业务流程和系统架构变得越来越重要。本文将教你如何结合使用ChatGPT和PlantUML,在Windows环境下快速高效地创建业务流程图、系统架构图等图形,并提供在线生成的方式。

为了存储和…
物模型是指…
IoT物模型是…
IoT数字孪生…

在使…